* Add models/tf.py for TensorFlow and TFLite export
* Set auto=False for int8 calibration
* Update requirements.txt for TensorFlow and TFLite export
* Read anchors directly from PyTorch weights
* Add --tf-nms to append NMS in TensorFlow SavedModel and GraphDef export
* Remove check_anchor_order, check_file, set_logging from import
* Reformat code and optimize imports
* Autodownload model and check cfg
* update --source path, img-size to 320, single output
* Adjust representative_dataset
* Put representative dataset in tfl_int8 block
* detect.py TF inference
* weights to string
* weights to string
* cleanup tf.py
* Add --dynamic-batch-size
* Add xywh normalization to reduce calibration error
* Update requirements.txt
TensorFlow 2.3.1 -> 2.4.0 to avoid int8 quantization error
* Fix imports
Move C3 from models.experimental to models.common
* Add models/tf.py for TensorFlow and TFLite export
* Set auto=False for int8 calibration
* Update requirements.txt for TensorFlow and TFLite export
* Read anchors directly from PyTorch weights
* Add --tf-nms to append NMS in TensorFlow SavedModel and GraphDef export
* Remove check_anchor_order, check_file, set_logging from import
* Reformat code and optimize imports
* Autodownload model and check cfg
* update --source path, img-size to 320, single output
* Adjust representative_dataset
* detect.py TF inference
* Put representative dataset in tfl_int8 block
* weights to string
* weights to string
* cleanup tf.py
* Add --dynamic-batch-size
* Add xywh normalization to reduce calibration error
* Update requirements.txt
TensorFlow 2.3.1 -> 2.4.0 to avoid int8 quantization error
* Fix imports
Move C3 from models.experimental to models.common
* implement C3() and SiLU()
* Add TensorFlow and TFLite Detection
* Add --tfl-detect for TFLite Detection
* Add int8 quantized TFLite inference in detect.py
* Add --edgetpu for Edge TPU detection
* Fix --img-size to add rectangle TensorFlow and TFLite input
* Add --no-tf-nms to detect objects using models combined with TensorFlow NMS
* Fix --img-size list type input
* Update README.md
* Add Android project for TFLite inference
* Upgrade TensorFlow v2.3.1 -> v2.4.0
* Disable normalization of xywh
* Rewrite names init in detect.py
* Change input resolution 640 -> 320 on Android
* Disable NNAPI
* Update README.me --img 640 -> 320
* Update README.me for Edge TPU
* Update README.md
* Fix reshape dim to support dynamic batching
* Fix reshape dim to support dynamic batching
* Add epsilon argument in tf_BN, which is different between TF and PT
* Set stride to None if not using PyTorch, and do not warmup without PyTorch
* Add list support in check_img_size()
* Add list input support in detect.py
* sys.path.append('./') to run from yolov5/
* Add int8 quantization support for TensorFlow 2.5
* Add get_coco128.sh
* Remove --no-tfl-detect in models/tf.py (Use tf-android-tfl-detect branch for EdgeTPU)
* Update requirements.txt
* Replace torch.load() with attempt_load()
* Update requirements.txt
* Add --tf-raw-resize to set half_pixel_centers=False
* Remove android directory
* Update README.md
* Update README.md
* Add multiple OS support for EdgeTPU detection
* Fix export and detect
* Export 3 YOLO heads with Edge TPU models
* Remove xywh denormalization with Edge TPU models in detect.py
* Fix saved_model and pb detect error
* [pre-commit.ci] auto fixes from pre-commit.com hooks
for more information, see https://pre-commit.ci
* Fix pre-commit.ci failure
* Add edgetpu in export.py docstring
* Fix Edge TPU model detection exported by TF 2.7
* Add class names for TF/TFLite in DetectMultibackend
* Fix assignment with nl in TFLite Detection
* Add check when getting Edge TPU compiler version
* Add UTF-8 encoding in opening --data file for Windows
* Remove redundant TensorFlow import
* Add Edge TPU in export.py's docstring
* Add the detect layer in Edge TPU model conversion
* Default `dnn=False`
* Cleanup data.yaml loading
* Update detect.py
* Update val.py
* Comments and generalize data.yaml names
Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com>
Co-authored-by: unknown <fangjiacong@ut.cn>
Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
|
||
|---|---|---|
| .github | ||
| data | ||
| models | ||
| utils | ||
| .dockerignore | ||
| .gitattributes | ||
| .gitignore | ||
| .pre-commit-config.yaml | ||
| CONTRIBUTING.md | ||
| Dockerfile | ||
| LICENSE | ||
| README.md | ||
| detect.py | ||
| export.py | ||
| hubconf.py | ||
| requirements.txt | ||
| setup.cfg | ||
| train.py | ||
| tutorial.ipynb | ||
| val.py | ||
README.md



YOLOv5 🚀 is a family of object detection architectures and models pretrained on the COCO dataset, and represents Ultralytics open-source research into future vision AI methods, incorporating lessons learned and best practices evolved over thousands of hours of research and development.
Documentation
See the YOLOv5 Docs for full documentation on training, testing and deployment.
Quick Start Examples
Install
Python>=3.6.0 is required with all requirements.txt installed including PyTorch>=1.7:
$ git clone https://github.com/ultralytics/yolov5
$ cd yolov5
$ pip install -r requirements.txt
Inference
Inference with YOLOv5 and PyTorch Hub. Models automatically download from the latest YOLOv5 release.
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5l, yolov5x, custom
# Images
img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
Inference with detect.py
detect.py runs inference on a variety of sources, downloading models automatically from
the latest YOLOv5 release and saving results to runs/detect.
$ python detect.py --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
Training
Run commands below to reproduce results
on COCO dataset (dataset auto-downloads on
first use). Training times for YOLOv5s/m/l/x are 2/4/6/8 days on a single V100 (multi-GPU times faster). Use the
largest --batch-size your GPU allows (batch sizes shown for 16 GB devices).
$ python train.py --data coco.yaml --cfg yolov5s.yaml --weights '' --batch-size 64
yolov5m 40
yolov5l 24
yolov5x 16

Tutorials
- Train Custom Data 🚀 RECOMMENDED
- Tips for Best Training Results ☘️ RECOMMENDED
- Weights & Biases Logging 🌟 NEW
- Roboflow for Datasets, Labeling, and Active Learning 🌟 NEW
- Multi-GPU Training
- PyTorch Hub ⭐ NEW
- TFLite, ONNX, CoreML, TensorRT Export 🚀
- Test-Time Augmentation (TTA)
- Model Ensembling
- Model Pruning/Sparsity
- Hyperparameter Evolution
- Transfer Learning with Frozen Layers ⭐ NEW
- TensorRT Deployment
Environments
Get started in seconds with our verified environments. Click each icon below for details.
Integrations
| Weights and Biases | Roboflow ⭐ NEW |
|---|---|
| Automatically track and visualize all your YOLOv5 training runs in the cloud with Weights & Biases | Label and export your custom datasets directly to YOLOv5 for training with Roboflow |
Why YOLOv5
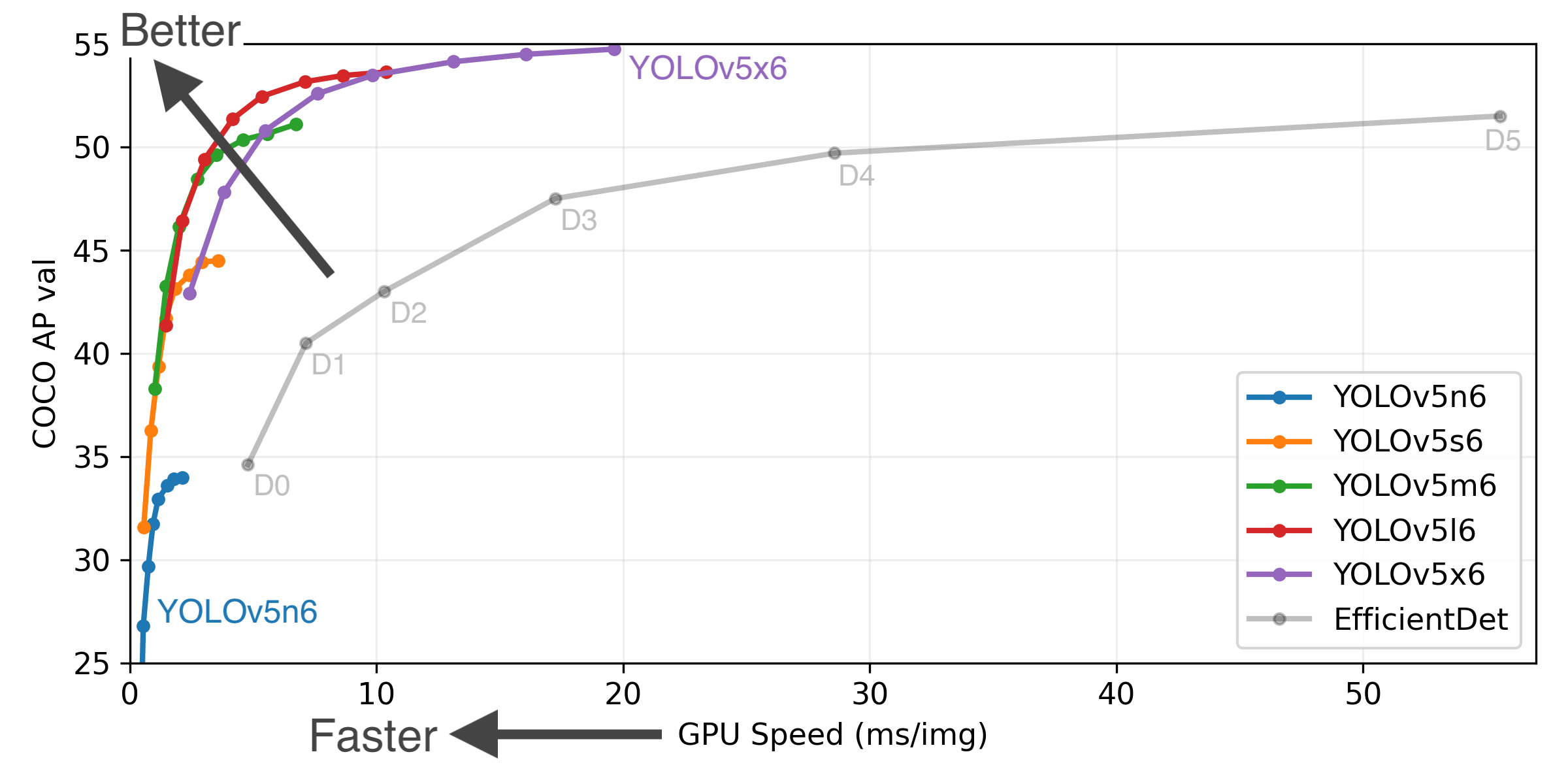
YOLOv5-P5 640 Figure (click to expand)
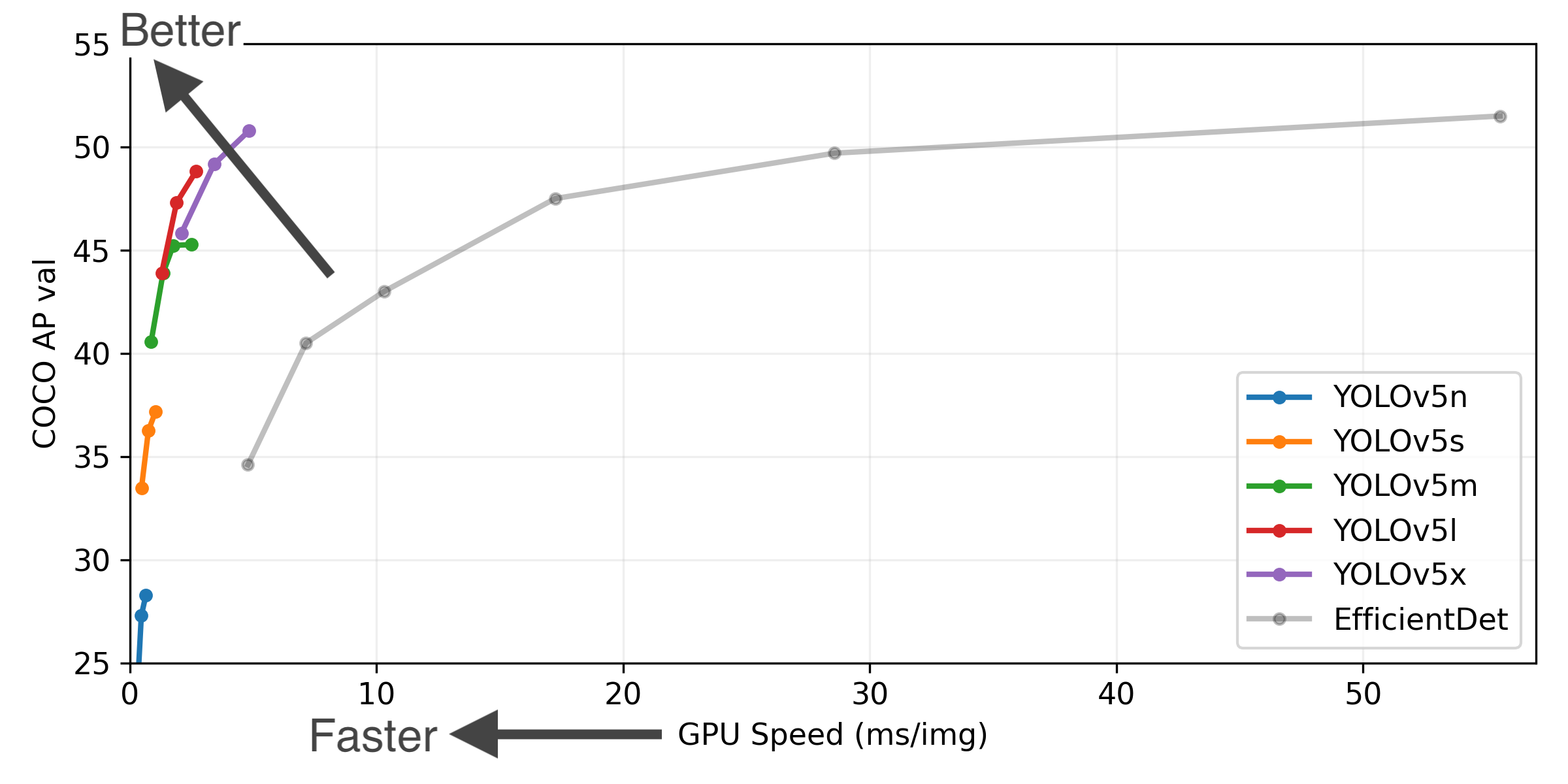
Figure Notes (click to expand)
- COCO AP val denotes mAP@0.5:0.95 metric measured on the 5000-image COCO val2017 dataset over various inference sizes from 256 to 1536.
- GPU Speed measures average inference time per image on COCO val2017 dataset using a AWS p3.2xlarge V100 instance at batch-size 32.
- EfficientDet data from google/automl at batch size 8.
- Reproduce by
python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt
Pretrained Checkpoints
| Model | size (pixels) |
mAPval 0.5:0.95 |
mAPval 0.5 |
Speed CPU b1 (ms) |
Speed V100 b1 (ms) |
Speed V100 b32 (ms) |
params (M) |
FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.4 | 46.0 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.2 | 56.0 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.2 | 63.9 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 48.8 | 67.2 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| YOLOv5n6 | 1280 | 34.0 | 50.7 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| YOLOv5s6 | 1280 | 44.5 | 63.0 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
| YOLOv5m6 | 1280 | 51.0 | 69.0 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| YOLOv5l6 | 1280 | 53.6 | 71.6 | 1784 | 15.8 | 10.5 | 76.7 | 111.4 |
| YOLOv5x6 + TTA |
1280 1536 |
54.7 55.4 |
72.4 72.3 |
3136 - |
26.2 - |
19.4 - |
140.7 - |
209.8 - |
Table Notes (click to expand)
- All checkpoints are trained to 300 epochs with default settings and hyperparameters.
- mAPval values are for single-model single-scale on COCO val2017 dataset.
Reproduce bypython val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65 - Speed averaged over COCO val images using a AWS p3.2xlarge instance. NMS times (~1 ms/img) not included.
Reproduce bypython val.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45 - TTA Test Time Augmentation includes reflection and scale augmentations.
Reproduce bypython val.py --data coco.yaml --img 1536 --iou 0.7 --augment
Contribute
We love your input! We want to make contributing to YOLOv5 as easy and transparent as possible. Please see our Contributing Guide to get started, and fill out the YOLOv5 Survey to send us feedback on your experiences. Thank you to all our contributors!

Contact
For YOLOv5 bugs and feature requests please visit GitHub Issues. For business inquiries or professional support requests please visit https://ultralytics.com/contact.